Temps de lecture estimé : 4 minutes
Introduction
L’encodage URL doit être appliqué chaque fois qu’il est nécessaire d’utiliser un caractère réservé dans une URL. Mais quels sont ces caractères réservés et qui les a définis ?
Les caractères réservés sont explicitement décrits dans la RFC 3986 : https://datatracker.ietf.org/doc/html/rfc3986#section-2.2
Il s’agit de
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
En d’autres termes : » : » , « , » , » ? » , « # » , « [ » , « ] » , « @ », » ! » , « $ » , « & » , « ‘ » , « ( » , « ) », « * » , « + » , « , » , » ; » , « = »
Pour décoder, vous devez savoir que les codes hexadécimaux de la table ASCII sont utilisés. Consultez le tableau dans le manuel :
man ascii
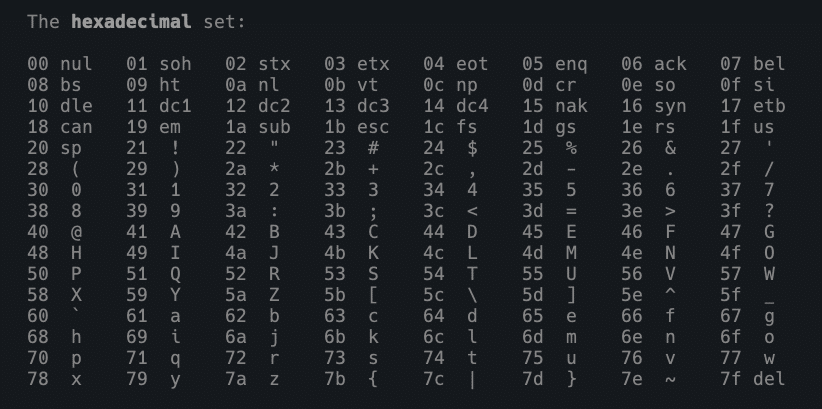
Les URL codés affichent le % avant chaque nombre hexadécimal dans la table ASCII. Par conséquent, pour créer l’encodage, il suffit de remplacer le caractère réservé par %hexadécimal! =D
Considérez que votre shell lira et interprétera l’hexadécimal avec le code d’échappement correspondant. Pour bash, nous utiliserons \x. Regardez le tableau ci-dessus et faites vos propres tests. Pour l’exclamation !, le code est 21. Jetez un coup d’œil :
$ echo -e "\x21" !
Remplacement par sed
Analysons une fonction simple avec sed pour effectuer le décodage :
#!/bin/bash
URL_DECODE="$(echo "$1" | sed -E 's/%([0-9a-fA-F]{2})/\\x\1/g;s/\+/ /g'"
echo -e "$URL_DECODE"
[0-9a-fA-F]{2}Fondamentalement, la commande sed s/%( )/\x\1/g remplace tous les % par des \x, à condition que les 2 caractères suivants représentent un nombre hexadécimal (de 00 à FF).
echo L’option -e de est alors activée pour interpréter cet hexadécimal.
s/\+/ /g Oh, et la deuxième commande sed remplace tous les signes + par des espaces =).
L’option -E de sed permet d’utiliser des expressions régulières modernes, afin d’éviter les nombreux caractères d’échappement qui perturbent la syntaxe.
Pour un script un peu plus sophistiqué, qui se charge également de l’encodage, nous utilisons plusieurs commandes sed à la suite.
Voir le code complet, qui inclut tous les caractères réservés de la RFC 3986 :
#!/bin/bash
#
# Enconding e Decoding de URL com sed
#
# Por Daniel Cambría
# [email protected]
#
# jul/2021
function url_decode() {
echo "$@" \
| sed -E 's/%([0-9a-fA-F]{2})/\\x\1/g;s/\+/ /g'
}
function url_encode() {
# Conforme RFC 3986
echo "$@" \
| sed \
-e 's/ /%20/g' \
-e 's/:/%3A/g' \
-e 's/,/%2C/g' \
-e 's/\?/%3F/g' \
-e 's/#/%23/g' \
-e 's/\[/%5B/g' \
-e 's/\]/%5D/g' \
-e 's/@/%40/g' \
-e 's/!/%41/g' \
-e 's/\$/%24/g' \
-e 's/&/%26/g' \
-e "s/'/%27/g" \
-e 's/(/%28/g' \
-e 's/)/%29/g' \
-e 's/\*/%2A/g' \
-e 's/\+/%2B/g' \
-e 's/,/%2C/g' \
-e 's/;/%3B/g' \
-e 's/=/%3D/g'
}
echo -e "URL decode: " $(url_decode "$1")
echo -e "URL encode: " $(url_encode "$1")
Note sur l’encodage des chaînes de requête
Le signe + apparaît souvent dans les URL pour remplacer l’espace. C’est le cas lorsque le texte se trouve dans une chaîne de requête. Voir cette section dans la RFC1866 : https://datatracker.ietf.org/doc/html/rfc1866#section-8.2.1
Mais pour tout autre codage HTML, vous devez utiliser le codage en pourcentage (codage URL).
Unicode
Bon, maintenant que vous avez compris la logique du truc, vous vous demandez sans doute : et si j’utilise des caractères accentués ?
Les accents ne figurent pas dans la table ASCII, mais dans la norme Unicode. Cette norme peut se présenter sous la forme d’UTF-8, d’UTF-16 et d’UTF-32 (UTF = Unicode Transformation Format, pour en savoir plus, consultez le site https://www.unicode.org/faq/utf_bom.html). Pour en savoir plus sur Unicode, consultez directement la source à l’adresse https://unicode.org/.
Si la valeur par défaut d’un nombre hexadécimal est \x, l’unicode est \u. Par exemple :
echo -e "\u2623" printf "\u2623" python -c 'print u"\u2623"'
Pour vérifier de quel code hexadécimal il s’agit, utilisez hexdump :
$ echo -en "☣" | hexdump 0000000 e2 98 a3 $ echo -e "\xe2\x98\xa3" ☣
Pour vérifier le code unicode à partir d’un code hexadécimal, cette partie du site Unicode qui consulte les tableaux de codes des caractères devrait suffire, mais elle n’accepte que l’hexadécimal UTF-16. Toutefois, il est possible de vérifier quel code Unicode correspond à l’hexadécimal UTF-8 grâce à la recherche effectuée par le site scarfboy. Consultez-le :
Unicode dans macOS bash
echo -e "\u2623"Sur MacOS, en raison de problèmes de licence logicielle avec bash à partir de la version 4.0, nous ne pouvons pas générer d’unicode comme ☣ avec .
brew install bashMais vous pouvez installer la version la plus récente de bash 5+ en utilisant .
Si vous n’avez jamais utilisé brew, il est très facile à installer, consultez le site de l’auteur https://brew.sh.Et dans cet autre article, la procédure pour faire du nouveau bash la version par défaut est très détaillée.
Heureusement, les utilisateurs de Linux n’auront pas ce problème.
=D
Si vous souhaitez générer une ENORME liste de caractères unicode, essayez le script ci-dessous.
chmod +x N’oubliez pas de le sauvegarder dans un fichier et de lui donner le droit d’exécution avec .
Si aucun caractère n’apparaît, relisez le paragraphe précédent et mettez à jour votre bash XD
#!/bin/bash
for y in $(seq 0 524287)
do
for x in $(seq 0 7)
do
a=$(expr $y \* 8 + $x)
echo -ne "$a \\u$a "
done
echo
done
Voir aussi
- Consultez la « table » officielle d’Unicode https://www.unicode .org/charts/
- Consultant avec de bonnes informations sur les caractères Unicode https://www.fileformat.info/info/unicode/char/2623/index.htm
- Un autre conseiller unicode intéressant https://unicode.scarfboy.com
- Comment convertir UTF https://www.unicode.org/faq/utf_bom.html#gen4
- En savoir plus sur la conversion UTF-8 https://www.fileformat.info/info/unicode/utf8.htm
Vous avez des questions ?
Postez-les dans les commentaires. À la prochaine fois !