Estimated reading time: 4 minutes
Introduction
URL encoding must be applied every time it is necessary to use a reserved character in a URL. But what are these reserved characters and who defined them?
The reserved characters are explicitly described in RFC 3986: https://datatracker.ietf.org/doc/html/rfc3986#section-2.2
They are:
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
In other words: “:” , “,” , “?” , “#” , “[” , “]” , “@”, “!” , “$” , “&” , “‘” , “(” , “)”, “*” , “+” , “,” , “;” , “=”
To make the decode, know that the hexadecimal codes in the ASCII table are used. Check out the table in the man:
man ascii
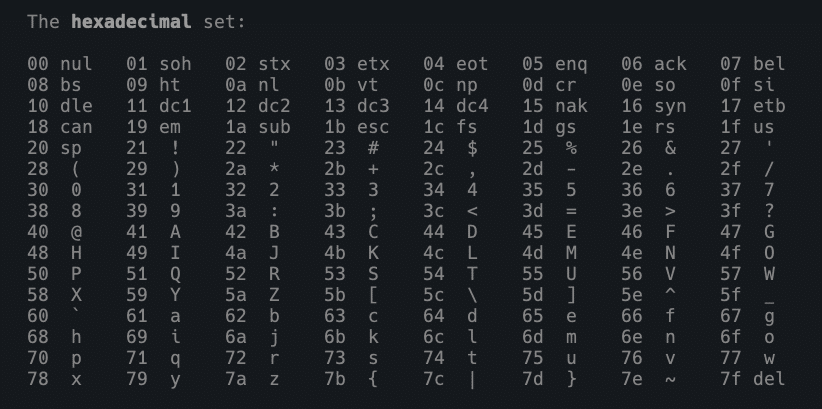
Encoded URLs display the % before each hexadecimal number in the ASCII table. Therefore, to create the encoding, simply replace the reserved character with %hexadecimal! =D
Consider that your shell will read and interpret the hexadecimal with the corresponding escape code. For bash, we’ll use \x. Look at the table above and do your own tests. For the exclamation !, the code is 21. See:
$ echo -e "\x21" !
Replacing with sed
Let’s analyze a simple function with sed to do the decode:
#!/bin/bash
URL_DECODE="$(echo "$1" | sed -E 's/%([0-9a-fA-F]{2})/\\x\1/g;s/\+/ /g'"
echo -e "$URL_DECODE"
Basically, the sed command s/%([0-9a-fA-F]{2})/\x\1/g replaces all % with \x, provided that the following 2 characters represent a hexadecimal number (from 00 to FF).
Then, the -e option of echo is activated to interpret this hexadecimal.
Oh, and the second sed command s/\+/ /g is replacing any + signs with space =).
The -E in sed is to enable the use of modern regular expressions, to avoid too many escape characters that clutter the syntax.
For a slightly more sophisticated script, which also does the encoding, then we use a bunch of sed commands in sequence.
See the complete code, which includes all the reserved characters from RFC 3986:
#!/bin/bash
#
# Enconding e Decoding de URL com sed
#
# Por Daniel Cambría
# [email protected]
#
# jul/2021
function url_decode() {
echo "$@" \
| sed -E 's/%([0-9a-fA-F]{2})/\\x\1/g;s/\+/ /g'
}
function url_encode() {
# Conforme RFC 3986
echo "$@" \
| sed \
-e 's/ /%20/g' \
-e 's/:/%3A/g' \
-e 's/,/%2C/g' \
-e 's/\?/%3F/g' \
-e 's/#/%23/g' \
-e 's/\[/%5B/g' \
-e 's/\]/%5D/g' \
-e 's/@/%40/g' \
-e 's/!/%41/g' \
-e 's/\$/%24/g' \
-e 's/&/%26/g' \
-e "s/'/%27/g" \
-e 's/(/%28/g' \
-e 's/)/%29/g' \
-e 's/\*/%2A/g' \
-e 's/\+/%2B/g' \
-e 's/,/%2C/g' \
-e 's/;/%3B/g' \
-e 's/=/%3D/g'
}
echo -e "URL decode: " $(url_decode "$1")
echo -e "URL encode: " $(url_encode "$1")
Note on encoding query strings
Often the + sign will appear in URLs to replace the space. This occurs when the text is in a query string. See this section in RFC1866: https://datatracker.ietf.org/doc/html/rfc1866#section-8.2.1
But for any other HTML encoding, you must use percent-encoding (URL encoding).
Unicode
Okay, now that you’ve understood the logic of the thing, you’re probably wondering: what if I use accented characters?
Well, accents are not in the ASCII table, but in the Unicode standard. This standard can appear as UTF-8, UTF-16 and UTF-32 (UTF= Unicode Transformation Format, read more at https://www.unicode.org/faq/utf_bom.html). You can find out more about Unicode directly from the source https://unicode.org/.
If the default for using a hexadecimal number is \x, the unicode is \u. For example:
echo -e "\u2623" printf "\u2623" python -c 'print u"\u2623"'
To check the hexadecimal code, use hexdump:
$ echo -en "☣" | hexdump 0000000 e2 98 a3 $ echo -e "\xe2\x98\xa3" ☣
To check the unicode code from a hexadecimal code, this area of the Unicode website which looks up the code charts of the characters should be enough, but it only accepts UTF-16 hexadecimal. However, it is possible to check which Unicode code is UTF-8 hexadecimal through the lookup that the scarfboy site performs. Check it out:
Unicode in MacOS bash
On MacOS, due to software licensing problems with bash from version 4.0 onwards, we can’t generate unicode like ☣ with echo -e "\u2623".
But you can install the very up-to-date bash 5+ using brew install bash.
If you’ve never used brew, it’s very easy to install, check out the author’s website https://brew.sh. And in this other article, the procedure for making the new bash the default is very detailed.
Fortunately, Linux users won’t have this problem.
=D
If you want to generate a HUGE list of unicode characters, try this script below.
Remember to save it in a file and give it executable permission with chmod +x.
If no characters appear, re-read the previous paragraph and update your bash XD
#!/bin/bash
for y in $(seq 0 524287)
do
for x in $(seq 0 7)
do
a=$(expr $y \* 8 + $x)
echo -ne "$a \\u$a "
done
echo
done
See also
- Check out the Official Unicode “Table” https://www.unicode.org/charts/
- Consultant with good information on Unicode characters https://www.fileformat.info/info/unicode/char/2623/index.htm
- Another interesting unicode advisor https://unicode.scarfboy.com
- How to convert UTF https://www.unicode.org/faq/utf_bom.html#gen4
- More about UTF-8 conversion https://www.fileformat.info/info/unicode/utf8.htm
Questions?
Post in the comments.
Until next time!