
Tempo estimado de leitura: 4 minutos
Introdução
O URL encoding deve ser aplicado toda vez que for necessário utilizar um caractere reservado numa URL. Mas o que são esses caracteres reservados e quem definiu isso?
Os caracteres reservados estão explicitamente descritos na RFC 3986: https://datatracker.ietf.org/doc/html/rfc3986#section-2.2
São eles:
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
Ou seja: “:” , “,” , “?” , “#” , “[” , “]” , “@”, “!” , “$” , “&” , “‘” , “(” , “)”, “*” , “+” , “,” , “;” , “=”
Para fazer o decode, saiba que utilizam-se os códigos hexadecimais da tabela ASCII. Confira a tabela pelo man:
man ascii
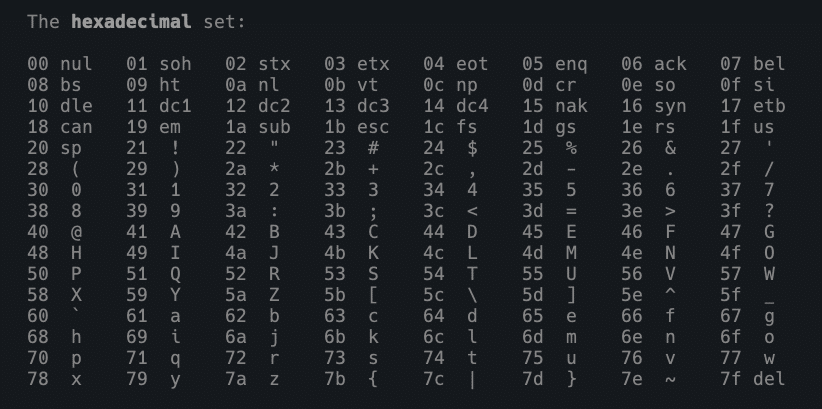
As URLs encodadas apresentam o % antes de cada número hexadecimal da tabela ASCII. Portanto, para criar o encoding, basta substituir o caractere reservado por %hexadecimal! =D
Considere que o seu shell vai ler interpretar o hexadecimal com o respectivo código de escape. Para o bash, vamos usar o \x. Veja a tabela acima e faça seus próprios testes. Para a exclamação !, o código é o 21. Veja:
$ echo -e "\x21" !
Substituindo com sed
Vamos analizar uma função simples com sed para fazer o decode:
#!/bin/bash
URL_DECODE="$(echo "$1" | sed -E 's/%([0-9a-fA-F]{2})/\\x\1/g;s/\+/ /g'"
echo -e "$URL_DECODE"
Basicamente o comando do sed s/%([0-9a-fA-F]{2})/\x\1/g substitui todos os % por \x, desde que os 2 caracteres seguintes representem um número hexadecimal (de 00 a FF). Depois, a opção -e do echo é ativada para interpretar esse hexadecimal. Ah, e o segundo comando do sed s/\+/ /g está substituindo eventuais sinais de + por espaço =). O -E do sed é para habilitar o uso de expressões regulares modernas, para evitar muitos caracteres de escape que sujam a sintaxe.
Para um script um pouco mais sofisticado, que também faça o encoding, daí usamos um monte de comandos sed na sequência.
Veja o código completo, que inclui todos os caracteres reservados da RFC 3986:
#!/bin/bash
#
# Enconding e Decoding de URL com sed
#
# Por Daniel Cambría
# [email protected]
#
# jul/2021
function url_decode() {
echo "$@" \
| sed -E 's/%([0-9a-fA-F]{2})/\\x\1/g;s/\+/ /g'
}
function url_encode() {
# Conforme RFC 3986
echo "$@" \
| sed \
-e 's/ /%20/g' \
-e 's/:/%3A/g' \
-e 's/,/%2C/g' \
-e 's/\?/%3F/g' \
-e 's/#/%23/g' \
-e 's/\[/%5B/g' \
-e 's/\]/%5D/g' \
-e 's/@/%40/g' \
-e 's/!/%41/g' \
-e 's/\$/%24/g' \
-e 's/&/%26/g' \
-e "s/'/%27/g" \
-e 's/(/%28/g' \
-e 's/)/%29/g' \
-e 's/\*/%2A/g' \
-e 's/\+/%2B/g' \
-e 's/,/%2C/g' \
-e 's/;/%3B/g' \
-e 's/=/%3D/g'
}
echo -e "URL decode: " $(url_decode "$1")
echo -e "URL encode: " $(url_encode "$1")
Nota sobre encoding de query strings
Muitas vezes o sinal de + irá aparecer em URLs para substituir o espaço. Isso ocorre quando o texto encontra-se numa query string. Veja este seção na RFC1866: https://datatracker.ietf.org/doc/html/rfc1866#section-8.2.1
Mas para qualquer outra codificação HTML, deve-se usar o percent-encoding (URL encoding).
Unicode
Ok, agora que você já entendeu a lógica da coisa, deve estar se perguntando: e se eu usar caracteres acentuados?
Bom, os acentuados não estão na tabela ASCII, mas no padrão Unicode. Esse padrão pode aparecer como UTF-8, UTF-16 e UTF-32 (UTF= Unicode Transformation Format, leia mais em https://www.unicode.org/faq/utf_bom.html). Você pode saber mais sobre Unicode direto da fonte https://unicode.org/.
Se o padrão para usar um número hexadecimal é \x, o unicode é \u. Por exemplo:
echo -e "\u2623" printf "\u2623" python -c 'print u"\u2623"'
Para verificar qual é o respectivo código hexadecimal, user o hexdump:
$ echo -en "☣" | hexdump 0000000 e2 98 a3 $ echo -e "\xe2\x98\xa3" ☣
Para conferir o código unicode a partir de um código hexadecimal, esta área do site da Unicode que faz lookup dos code charts dos caracteres deveria ser o suficiente, mas ele só aceita hexadecimal de UTF-16. Mas é possível consultar qual o código unicode de hexadecimal de UTF-8 através do lookup que o site scarfboy realiza. Dê uma conferida:
Unicode no bash do MacOS
No MacOS, por problemas licenciamento de software com o bash a partir da versão 4.0, não conseguimos gerar unicode como ☣ com echo -e "\u2623". Mas você pode instalar o bash 5+ atualizadíssimo usando brew install bash. Se nunca usou o brew, é bem fácil de instalar, consulte o site do autor https://brew.sh. E neste outro artigo, está bem detalhado o procedimento para tornar o novo bash como padrão. Felizmente, usuários de linux não terão esse problema. =D
Se quiser gerar uma lista ENORME de caracteres unicode, experimente esse script abaixo. Lembre-se de salvá-lo num arquivo e dar permissão de executável com chmod +x . Caso não apareça nenhum caractere, releia o parágrafo anterior e atualize seu bash XD
#!/bin/bash
for y in $(seq 0 524287)
do
for x in $(seq 0 7)
do
a=$(expr $y \* 8 + $x)
echo -ne "$a \\u$a "
done
echo
done
Veja também
- Confira a “Tabela” Unicode Oficial https://www.unicode.org/charts/
- Consultor com boas informações sobre caracteres unicode https://www.fileformat.info/info/unicode/char/2623/index.htm
- Outro consultor unicode interessante https://unicode.scarfboy.com
- Como converter UTF https://www.unicode.org/faq/utf_bom.html#gen4
- Mais sobre conversão UTF-8 https://www.fileformat.info/info/unicode/utf8.htm
Dúvidas? Poste nos comentários.
Até a próxima!







Uma resposta
Sensacional! Excelente ponto sobre encoding de query strings!